
Disponibilidad de datos FAQ
¿Qué es la disponibilidad de datos?
La disponibilidad de datos responde a la pregunta, ¿se han publicado estos datos? Específicamente, un nodo verificará la disponibilidad de datos cuando reciba un nuevo bloque que se está agregando a la cadena. El nodo intentará descargar todos los datos de la transacción para el nuevo bloque para verificar la disponibilidad. Si el nodo puede descargar todos los datos de la transacción, entonces verificó con éxito la disponibilidad de datos, lo que demuestra que los datos del bloque se publicaron realmente en la red.
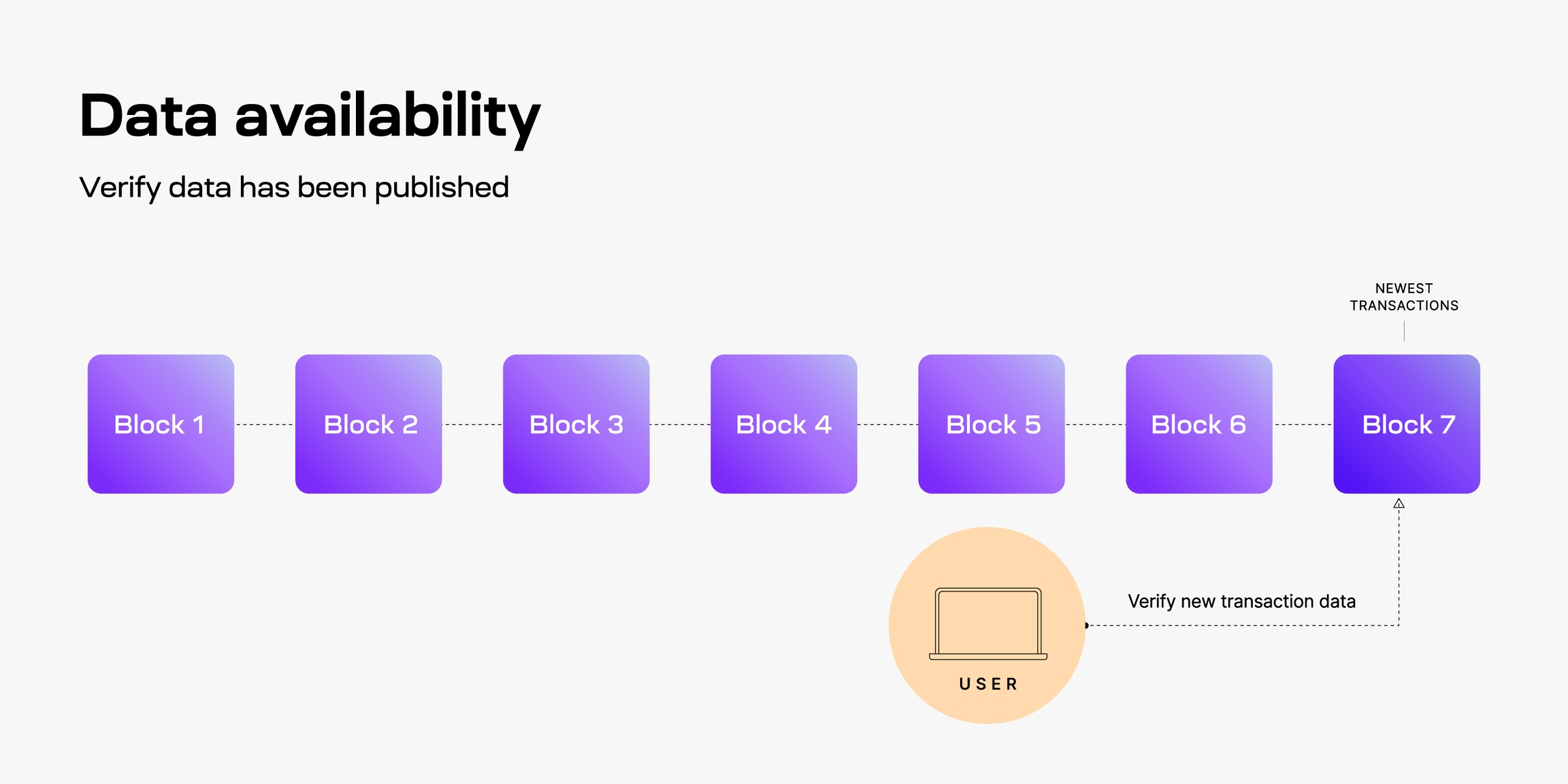
Como verá, las cadenas de bloques modulares como Celestia emplean otras primitivas que permiten a los nodos verificar la disponibilidad de datos de manera más eficiente. La disponibilidad de datos es fundamental para la seguridad de cualquier cadena de bloques porque garantiza que cualquiera pueda inspeccionar el libro mayor de las transacciones y verificarlo. La disponibilidad de datos se vuelve particularmente problemática cuando se escalan cadenas de bloques. A medida que los bloques se hacen más grandes, se vuelve poco práctico para los usuarios normales descargar todos los datos y, por lo tanto, los usuarios ya no pueden verificar la cadena.
¿Cuál es el problema de disponibilidad de datos?
El problema con la disponibilidad de datos ocurre cuando los datos de transacción para un bloque recientemente propuesto no se pueden descargar y verificar. Este tipo de ataque de un productor de bloques se llama ataque de retención de datos, que ve al productor de bloques retener datos de transacción de un nuevo bloque.
Dado que los datos de transacción se retienen, los nodos no pueden actualizarse al estado más reciente. Tal ataque puede tener numerosas consecuencias, desde detener una cadena hasta obtener la capacidad de robar fondos. La gravedad de las consecuencias dependerá del tipo de blockchain (L1 o L2) y de si la disponibilidad de datos se mantiene en cadena o fuera de cadena. El problema de disponibilidad de datos surge comúnmente en torno a soluciones de escalado L2 como rollups y validiums.
¿Cómo verifican los nodos la disponibilidad de datos en Celestia?
En la mayoría de las cadenas de bloques, los nodos que verifican la disponibilidad de datos lo hacen descargando todos los datos de transacciones para un bloque. Si pueden descargar todos los datos, han verificado su disponibilidad. En Celestia, los nodos de luz tienen acceso a un nuevo mecanismo para verificar la disponibilidad de datos sin necesidad de descargar todos los datos para un bloque. Esta nueva primitiva para verificar la disponibilidad de datos se denomina muestreo de disponibilidad de datos.
¿Qué es el muestreo de disponibilidad de datos?
El muestreo de disponibilidad de datos es un mecanismo para que los nodos de luz verifiquen la disponibilidad de datos sin tener que descargar todos los datos para un bloque. El muestreo de disponibilidad de datos (DAS) funciona haciendo que los nodos de luz realicen múltiples rondas de muestreo aleatorio para pequeñas porciones de datos de bloques. A medida que un nodo de luz completa más rondas de muestreo para datos de bloque, aumenta su confianza en que los datos están disponibles. Una vez que el nodo de luz alcanza con éxito un nivel de confianza predeterminado (por ejemplo, 99%), considerará los datos de bloque como disponibles.
¿Quieres una explicación más simple? Mira este hilo sobre cómo el muestreo de disponibilidad de datos es como voltear una moneda.
¿Cuáles son algunos de los supuestos de seguridad que Celestia hace para el muestreo de disponibilidad de datos?
Celestia asume que hay un número mínimo de nodos de luz que están llevando a cabo el muestreo de disponibilidad de datos para un tamaño de bloque determinado. Esta suposición es necesaria para que un nodo completo pueda reconstruir un bloque completo a partir de las porciones de nodos de luz de datos muestreados y almacenados. La cantidad de nodos de luz que se necesitan dependerá del tamaño del bloque: para bloques más grandes, se supone que se están ejecutando más nodos de luz.
Una segunda suposición notable que se hace por los nodos de luz es que están conectados a al menos un nodo completo honesto. Esto garantiza que puedan recibir pruebas de fraude para borrar incorrectamente bloques codificados. Si un nodo de luz no está conectado a un nodo completo honesto, como durante un ataque de eclipse, no puede verificar que el bloque esté construido incorrectamente.
¿Por qué es necesaria la reconstrucción de bloques para la seguridad?
En Celestia, los bloques deben borrarse codificados para que haya datos redundantes que ayuden al proceso de muestreo de disponibilidad de datos. Sin embargo, los nodos encargados de la codificación de borrado de los datos podrían hacerlo incorrectamente. Dado que Celestia utiliza pruebas de fraude para verificar que la codificación de borrado es incorrecta, se necesitan los datos de bloque completos para generar una prueba de fraude de codificación incorrecta.
Podría haber una situación en la que los validadores solo proporcionen datos a los nodos ligeros y no a los nodos completos. Si los nodos completos no tienen la capacidad de reconstruir el bloque completo a partir de las porciones de datos almacenados por los nodos ligeros, no podrían generar una prueba de fraude de codificación incorrecta.
¿Qué es el almacenamiento de datos?
El almacenamiento de datos se refiere a la capacidad de almacenar y acceder a datos de transacciones pasadas.
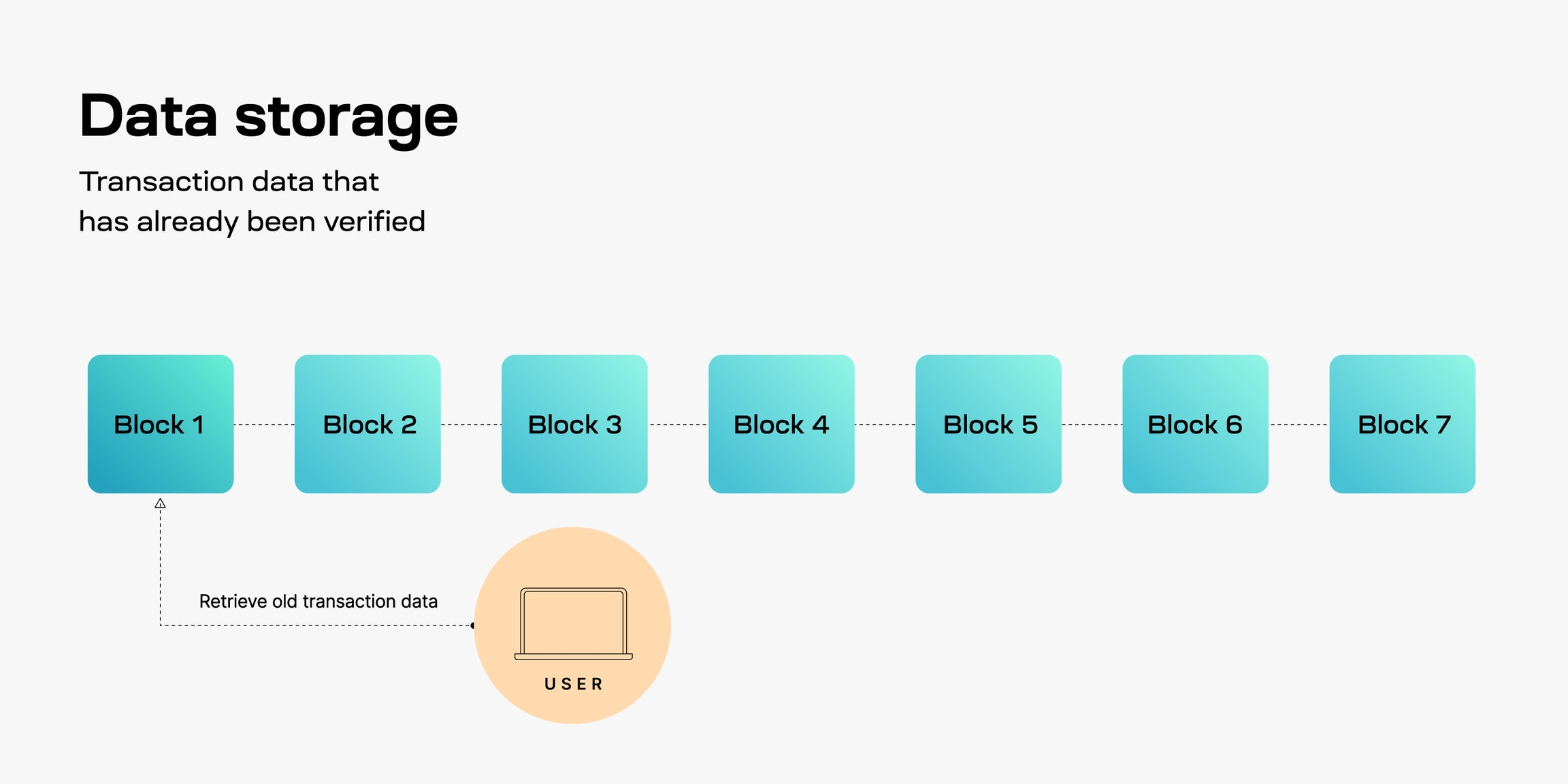
El almacenamiento y recuperación de datos es necesario para múltiples propósitos, tales como:
Leer la información de una transacción anterior
Sincronizar un nodo
Indexación y servicio de datos de transacciones
Recuperar información de NFT
¿Cuál es el problema en torno al almacenamiento de datos?
El problema con el almacenamiento de datos es si los datos de transacciones pasadas se pueden almacenar y recuperar con éxito en un momento posterior. La incapacidad de recuperar datos históricos de transacciones puede causar problemas, como que los usuarios no puedan acceder a información sobre sus transacciones pasadas o nodos que no pueden sincronizarse desde la génesis. Afortunadamente, las suposiciones sobre el almacenamiento y el acceso a datos pasados son débiles. Solo una sola copia del historial de una cadena de bloques debe ser accesible para que los usuarios obtengan acceso a los datos históricos de las transacciones. En otras palabras, la seguridad del almacenamiento de datos es una suposición de honestidad 1 de N.
¿Cuál es la diferencia entre la disponibilidad de datos y el almacenamiento de datos?
La disponibilidad de datos consiste en verificar que los datos de transacción para un nuevo bloque sean públicos y estén disponibles. Por el contrario, el almacenamiento de datos implica almacenar y acceder a datos de transacciones pasadas desde bloques antiguos.
¿Dónde encaja el estado de blockchain en esto?
Hasta ahora se trata de datos de transacciones, pero el estado de blockchain es un tema relacionado. El estado es diferente de los datos de transacción. Específicamente, el estado es como una instantánea actual de la red, que incluye información sobre saldos de cuentas, saldos de contratos inteligentes e información del conjunto de validadores. Problemas que surgen del tamaño del estado son diferentes en naturaleza que los relacionados con la disponibilidad de datos y la capacidad de recuperación.
¿Por qué Celestia incentiva el almacenamiento de datos históricos?
La mayoría de las cadenas de bloques no incentivan el almacenamiento de datos porque no debería ser responsabilidad de una cadena de bloques garantizar que los datos pasados se puedan recuperar para siempre. Además, el problema de almacenamiento de datos solo requiere que una sola parte almacene y proporcione los datos a los usuarios, lo que no es un problema importante. Como tal, el propósito de Celestiaia es proporcionar una forma segura y escalable de verificar la disponibilidad de los datos. Una vez que los datos se han verificado como disponibles, el trabajo de almacenar y recuperar datos históricos se deja a otras entidades que requieren los datos. Afortunadamente, existen incentivos naturales para que las partes externas almacenen y sirvan datos históricos a los usuarios.
¿Quién puede almacenar datos históricos si no hay recompensa?
Hay múltiples tipos de actores que pueden almacenar datos históricos. Algunos de ellos incluyen:
Exploradores de bloques que proporcionan acceso a datos de transacciones pasadas.
Indexadores que proporcionan consultas de API para datos pasados.
Aplicaciones o rollups que requieren datos históricos para ciertos procesos.
Usuarios que quieran garantizar que tendrán acceso a su historial de transacciones.
¿Cuáles son algunas cosas que las cadenas de bloques pueden hacer para proporcionar garantías más sólidas de recuperación de datos?
Nodos de recompensa basados en la cantidad de datos de transacciones que almacenan y las solicitudes de datos que sirven (este es el caso de algunas cadenas de bloques de almacenamiento de datos, como Filecoin).
Publique datos de transacciones en una cadena de bloques de almacenamiento de datos que incentive el almacenamiento y el servicio de solicitudes de datos históricos.
Last updated